

Felsöka en seg eller nedlagd VPS – diagnos och åtgärd
Servern svarar inte, eller besökarna ser ett 502-fel. Innan du trycker på omstart, börja med att ta reda på vad som faktiskt gick fel. En omstart kan maskera grundorsaken och du hamnar i samma situation igen inom några dagar. Den här guiden tar dig igenom en strukturerad diagnos, från det vanligaste felet till det mer sällsynta, med konkreta terminalkommandon vid varje steg.
Förutsättningen är att du kan logga in via SSH. Om SSH-åtkomsten inte fungerar alls behöver du använda din leverantörs webbkonsol (kallas VNC-konsol, Emergency Console eller KVM-konsol beroende på leverantör) och komma in därifrån. De flesta svenska VPS-leverantörer, som GleSYS, Oderland och Inleed, erbjuder den här typen av konsollösning i sin kontrollpanel.
Guiden täcker Ubuntu och Debian. Kör du AlmaLinux eller Rocky Linux gäller samma kommandon i de allra flesta fall, men pakethanteraren heter dnf istället för apt. Har du ännu inte satt upp din VPS rekommenderar vi att du börjar med vår guide Så kommer du igång med din första VPS.
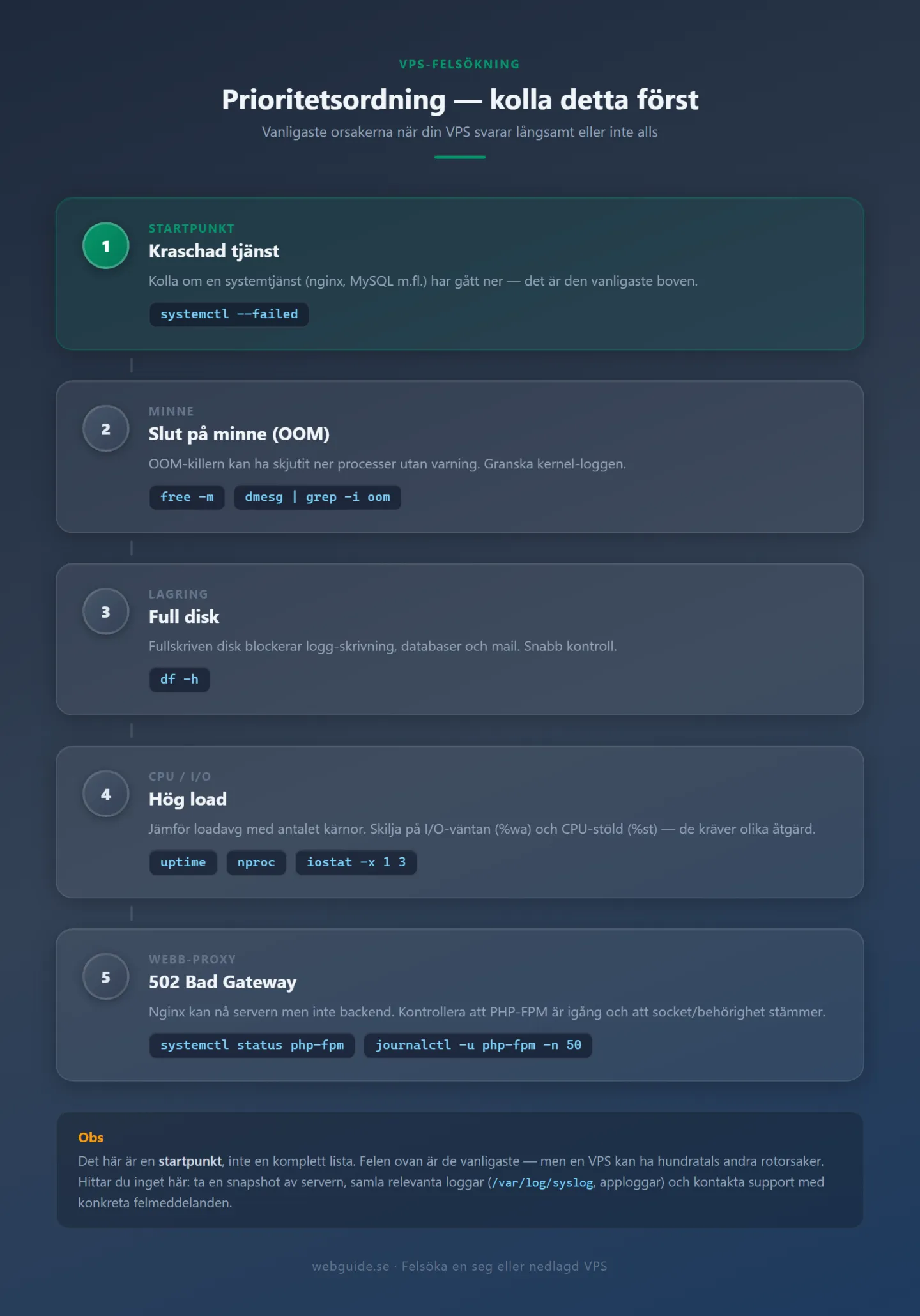
Steg 1: Är servern nere eller är det en tjänst som kraschat?
Det första du behöver avgöra är om servern själv svarar, eller om det är en specifik tjänst (webbservern, PHP-tolken, databasen) som har stannat. Det avgör helt vilka verktyg du ska använda härnäst.
Testa från insidan av servern:
curl -I http://localhostSvarar den med en HTTP-statuskod, även om det är ett felmeddelande? Då lever servern och problemet ligger i en tjänst eller i nätverket utåt, inte i infrastrukturen. Testa sedan utifrån:
ping din-server-ipOm IP-adressen inte svarar alls är det troligen ett problem på hypervisor- eller nätverksnivå hos leverantören, vilket du inte kan åtgärda från terminalen. Kontrollera leverantörens statussida och kontakta support med information om när felet uppstod.
En snabb överblick över alla tjänster som har feiltillstånd just nu:
systemctl list-units --state=failedSer du namn du känner igen, till exempel nginx, php8.3-fpm eller mysql? Gå vidare till steg 2.
Steg 2: Kontrollera tjänsternas status
En kraschad tjänst är den vanligaste orsaken till att en VPS verkar nere, och det är oftast det snabbaste att rätta till. Det typiska scenariot är att nginx eller Apache lever men inte kan nå backendprocessen (PHP-FPM, din Node.js-app), vilket resulterar i ett 502-fel mot besökaren.
Identifiera kraschad tjänst
Kör statuskontroll på de tjänster som är relevanta för din server:
systemctl status nginx
systemctl status apache2
systemctl status php8.3-fpm
systemctl status mysqlEn köpande tjänst visar Active: active (running). En kraschad visar Active: failed eller Active: inactive (dead). I utdatan hittar du också de sista loggraderna och en exit-kod. exit-code 1 pekar vanligen på ett konfigurationsfel, medan signal: killed tyder på att processen tvångsdödades av kärnan, ofta på grund av minnesbrist.
Läs loggen för att förstå varför
Att starta om tjänsten utan att förstå orsaken löser ingenting på sikt. Läs vad som hände:
journalctl -u nginx --since "10 minutes ago"
journalctl -xeVill du läsa nginx felloggen direkt:
tail -n 50 /var/log/nginx/error.logFör Apache respektive PHP-FPM (anpassa versionsnumret efter det som är installerat på din server):
tail -n 50 /var/log/apache2/error.log
tail -n 50 /var/log/php8.3-fpm.logStarta om tjänsten
Verifiera alltid konfigurationen innan du startar om. En omstart med trasig konfiguration gör att tjänsten inte startar alls:
sudo nginx -t
sudo systemctl restart nginxMotsvarande test för Apache heter apache2ctl configtest. Om tjänsten inte är konfigurerad att starta automatiskt efter omstart av servern, kontrollera:
sudo systemctl enable nginxSteg 3: Minnesbrist och OOM-kills
Tjänster som dör utan uppenbar anledning, ofta mitt i natten eller under trafikstoppar, är ett klassiskt tecken på att Linux OOM-killer har ingripit. OOM-killer (Out of Memory Killer) är kärnans skyddsmekanism: när det inte finns tillräckligt med RAM kvar tvingas den döda processer för att förhindra att hela systemet låser sig.
Är OOM-killer inblandad?
dmesg -T | grep -i "oom\|killed\|out of memory"Du letar efter rader i stil med oom-kill event följt av processnamn och PID, samt Killed process. Tidsstämplarna i dmesg -T hjälper dig sätta händelsen i relation till när felet uppträdde. Alternativt via journalctl:
journalctl -k | grep -i "oom\|killed"Hur mycket minne används just nu?
free -mKolumnen som heter available är det som faktiskt är tillgängligt för nya processer, inte kolumnen free. En server med 50 MB available och 1 GB used är nära gränsen. Kontrollera om servern swapar aktivt:
vmstat 1 5Kolumnerna si (swap in) och so (swap out) är det du tittar på. Är de konstant över noll under alla fem mätpunkterna är servern i swap-thrashing och upplevs som praktiskt taget obrukbar, även om den tekniskt sett lever.
Vad äter minnet?
ps aux --sort=-%mem | head -15Vanliga syndare är MySQL och MariaDB med generöst tilltagna bufferpooler, PHP-FPM workers som staplas upp vid trafiktoppar, och Java-baserade applikationer. En server som har kört länge utan omstart kan också ha minnesfragmentering som gradvis minskar det användbara RAM.
Kortsiktig åtgärd och vad du gör på längre sikt
Den omedelbara åtgärden är att starta om den drabbade tjänsten (nu vet du varför den kraschade). Driver MySQL problemet kan du sänka innodb_buffer_pool_size i konfigurationsfilen som ett snabbt ingrepp.
Swap fungerar som ett säkerhetsnät och en vanlig tumregel är 1 till 2 gånger RAM:et, upp till 4 GB. På moderna SSD-servrar behövs swap ofta inte alls, men en liten swap ger ett par sekunders varning istället för en omedelbar krasch. Glöm inte att swap är tiotals till hundratals gånger långsammare än RAM. En server som konstant swapar är inte lösad, den är seg.
Upprepar sig OOM-problemet är du troligen vid din VPS-plans gräns. Då är det dags att antingen öka RAM-tilldelningen eller titta på en managed VPS om felsökning tar för mycket tid. Se också FAQ:en om hur mycket RAM och CPU din VPS egentligen behöver.
Steg 4: Full disk
Diskfyllning är tyst och underskattad. Tjänster börjar bete sig märkligt, loggar skrivs inte, databastransaktioner misslyckas, och inget av felmeddelandena pekar direkt på disken. Börja med en snabb översikt:
df -hLetar du efter 100 procent på / eller /var. Hitta sedan vad som tar plats:
du -sh /var/log/* | sort -rh | head -20
du -sh /var/www/* | sort -rh | head -10Vanliga bovar är roterade loggar som inte rensas ordentligt, MySQL binlog som växer obegränsat, PHP-sessioner som samlas i /var/lib/php/sessions/, och backupfiler som hamnat i fel katalog. Att töm en loggfil akut görs säkrast med:
sudo truncate -s 0 /var/log/nginx/access.logVarför inte rm? Om nginx fortfarande håller filen öppen frigörs diskutrymmet inte förrän processen startas om. Trunkering fungerar omedelbart. Städa sedan upp paket och apt-cache:
sudo apt autoremove && sudo apt cleanVill du ha en mer lättläst bild av diskslöseriet kan du installera ncdu, ett interaktivt verktyg som låter dig navigera kataloger och se vad som tar plats.
Steg 5: Hög load average och CPU-starvation
Den här typen av problem är mer svårfångad: servern lever, SSH fungerar, men allt svarar långsamt och webbsidan laddas i snigeltakt eller timeout:ar.
Förstå load average
uptimeUtdatan visar load average för de senaste 1, 5 och 15 minuterna. Det viktiga är att sätta siffran i relation till antalet vCPU-kärnor, inte läsa den som ett absolut tal:
nprocEn tumregel är att ett load average ungefär lika med antalet kärnor innebär full utnyttjning. Dubbelt antalet kärnor under mer än fem minuter betyder att processer köar. På en VPS med 2 kärnor är load average 4 ett tydligt problem. På en med 8 kärnor är det gott om utrymme kvar.
Hitta den skyldige
topTryck P inuti top för att sortera på CPU-användning. Vill du ha en statisk snapshot att kopiera och spara:
ps aux --sort=-%cpu | head -15Vanliga orsaker till hög load är PHP-skript i oändliga loopar, MySQL-frågor utan index mot stora tabeller, bakgrundsjobb (cron) som staplar sig för att föregående körning inte avslutats, och aggressiva skrapbotar som hammrar sajten utan hänsyn till crawl-fördröjning.
Hög load men låg CPU: servern väntar på disken
Ett av de mest förvirrande scenarierna är när load average är skyhögt men top visar att CPU:n knappt jobbar. Då är det nästan alltid disken som är flaskhalsen. Load average räknar inte bara processer som kör, utan även de som sitter fast och väntar på en I/O-operation. På en VPS med delad eller strypt lagring är det här en vanlig orsak till att servern känns frusen.
I top tittar du på %wa på CPU-raden, det står för I/O-wait. Är det talet högt väntar processer på lagringen. Processer som fastnat i väntan visas med status D (uninterruptible sleep) och går inte ens att döda förrän operationen slutförts:
ps aux | awk '$8 ~ /D/'För att se vilken disk och vilken process som belastar lagringen, installera sysstat respektive iotop:
iostat -x 1 5
sudo iotop -oKolumnen %util i iostat nära 100 procent betyder att disken är mättad. Är det återkommande på en VPS med strypt I/O är det ett tecken på att planen är för liten för din arbetsbelastning, eller att en grannserver tar lagringsbandbredd.
CPU steal
Det finns ett prestandafenomen som är unikt för VPS-miljöer och som sällan förklaras på svenska. I top finns det en kolumn som heter %st: det är CPU steal. Det mäter hur stor andel av tiden din vCPU tvingas vänta på att den fysiska CPU:n på hypervisorn ska bli ledig, för att en grannserver på samma fysiska maskin tar resurser.
topTryck 1 för att se statistik per CPU-kärna, inklusive steal-kolumnen. En branschumregel är att steal-värden konstant över 10 till 15 procent är ett tecken på att hypervisorns fysiska server är överbelastad. Det är ingenting du kan åtgärda själv. Kontakta din leverantör, dokumentera tidpunkter och värden, och be om att migreras till en annan nod. Hjälper inte det är det ett tecken på att byta leverantör.
Om det är disk-I/O som skapar flaskhalsen snarare än CPU kan du installera iotop (sudo apt install iotop) för att se exakt vilken process som hammrar lagringen.
Steg 6: 502 Bad Gateway: checklista
502 Bad Gateway är det felmeddelande som läsare oftast söker på, och det förtjänar ett eget samlat avsnitt. Felet innebär att din webbserver (nginx, Apache) lever men inte kan nå backendprocessen. Jämför med 504 Gateway Timeout, som innebär att backenden svarar men tar för lång tid. Diagnosen är liknande men 504 pekar mer på en långsam applikation än en kraschad.
Kör igenom dessa punkter i ordning:
- Är PHP-FPM igång? Det vanligaste skälet till 502 på WordPress-servrar.
systemctl status php8.3-fpm - Är din appserver igång? Kör du Node.js, Python eller Ruby körs din app vanligtvis som en systemd-tjänst.
systemctl status din-applikation - Läs nginx-loggen:
Leta efter fraser somtail -50 /var/log/nginx/error.logconnect() failed,no live upstreamsellerconnect to unix:/run/php/php8.3-fpm.sock failed. - Lyssnar PHP-FPM på rätt socket eller port?
Standardkonfigurationen på Ubuntu använder ofta en Unix-socket (ss -tlnp | grep :9000/run/php/php8.3-fpm.sock) snarare än port 9000. Kontrollera att din nginx-konfiguration och PHP-FPM-konfigurationen är överens om vilket alternativ som används. - Har nginx behörighet till socketen? En vanlig och förbisedd orsak: socketen finns men nginx-användaren får inte läsa den. Kontrollera ägare och läge, och att
listen.owner/listen.groupi PHP-FPM-poolen matchar nginx-användaren (oftastwww-data).ls -l /run/php/php8.3-fpm.sock - Testa backenden direkt, utan nginx i bilden: svarar den, ligger felet i nginx-konfigurationen; svarar den inte, ligger felet i backenden.
curl --unix-socket /run/php/php8.3-fpm.sock http://localhost/ - Kontrollera nginx-konfigurationen:
sudo nginx -t - OOM-kill nyligen? Se steg 3 ovan.
dmesg -T | grep -i "killed"
Hjälper inte checklistan finns två mindre uppenbara orsaker. Stora svarsheaders (till exempel tunga cookies eller långa omdirigeringskedjor) kan spränga nginx buffertar och ge 502, vilket åtgärdas genom att höja fastcgi_buffers respektive proxy_buffer_size. Tar backenden för lång tid på sig blir det däremot oftare ett 504 Gateway Timeout, som du justerar med fastcgi_read_timeout eller proxy_read_timeout. Kör du AlmaLinux eller Rocky Linux kan SELinux blockera nginx från att nå backenden trots att allt annat ser rätt ut. Kontrollera med sudo ausearch -m avc -ts recent, och tillåt vid behov nätverksanslutningar med sudo setsebool -P httpd_can_network_connect 1.
journalctl: de kommandon du faktiskt behöver
journalctl är det mest effektiva diagnostikverktyget på ett modernt Linux-system, men det upplevs som överväldigande av många halvtekniska användare. Det behöver det inte vara. De fem kommandon som täcker de allra flesta felsökningssituationer:
journalctl -xeVisar de senaste loggposterna med förklarande kontext. Startpunkten när du inte vet vad du letar efter.
journalctl -u nginxVisa loggar för en specifik tjänst. Byt ut nginx mot valfritt tjänstnamn.
journalctl --since "1 hour ago"Filtrerat på tid. Kombinera med -u för att begränsa till en tjänst under en tidsperiod.
journalctl -kBara kärnloggar, motsvarar dmesg. Bra för att hitta OOM-händelser och hårdvaruvarningar.
journalctl --disk-usageHur stor plats loggar tar på disken. Relevant om df -h visar att /var är full.
Vill du följa loggen i realtid fungerar journalctl -f precis som tail -f fast för hela systemet.
När du inte hittar orsaken: eskaleringskedjan
Har du kört igenom stegen ovan utan att hitta en tydlig orsak, gör det i den här ordningen innan du tar till drastiska åtgärder:
- Ta en snapshot via leverantörens kontrollpanel innan du gör fler ändringar. Det ger dig en säker utgångspunkt att återgå till.
- Kontrollera leverantörens statussida. Är det ett hypervisor- eller nätverksproblem på deras sida syns det inte i din terminal.
- Kontakta leverantörens support med loggar bifogade. De kan se saker på hypervisor-nivå som du inte har tillgång till. Tidsstämplar och utdata från
dmesg,journalctl -xeochfree -mär värdefullt att bifoga. - Är problemet återkommande? Dags att utvärdera uppgradering till mer resurser, eller att byta till en managed VPS om felsökning tar för mycket av din tid. Jämför VPS-planer för att se vilka alternativ som finns.
- Reinstallera OS är sista utvägen. Utan att veta grundorsaken kommer problemet tillbaka. Gör det bara om du har fullständig backup och grundorsaken är okänd och okontrollerbar.
Är du osäker på om unmanaged VPS är rätt val för dig finns en genomgång i vår artikel om managed vs unmanaged VPS. Och om servern är underspecad för din trafik, fundera på om det är dags att uppgradera din plan.
Förhindra nästa incident
En incident är ett bra tillfälle att sätta upp de skydd som gör att du inte behöver gå igenom samma process om tre veckor.
Övervakningsvarning. Sätt upp en enkel uptimekontroll som skickar SMS eller e-post när servern slutar svara. Det finns gratisnivåer hos flera tjänster som kontrollerar din server var femte minut. Du behöver inte veta att servern är nere för att en besökare ska berätta det.
Automatiska säkerhetsuppdateringar. Paketet unattended-upgrades på Ubuntu och Debian tar hand om kritiska säkerhetspatchar utan att du behöver manuellt köra apt upgrade varje vecka. Det minskar risken för att en känd sårbarhet utnyttjas och orsakar problem.
Backup som faktiskt fungerar. Din leverantörs automatiska snapshot är ett bra komplement men inte ett fullständigt skydd. En snapshot på samma infrastruktur skyddar inte mot leverantörsproblem. Läs mer om hur du sätter upp backup på din VPS med en strategi som ger dig ett externt alternativ.
Vill du ha realtidsinsyn i serverns resursutnyttjning finns verktyg som Netdata (lättinstallerat, gratis självhostat) och Prometheus med Grafana för den som vill ha ett mer komplett övervakningsupplägg. De kräver en separat guide, men principen är densamma: se problemen komma innan de slår ner.